
Before describing particular components of the IOC software, it is helpful to give an overview of three closely related topics: Database locking, scanning, and processing. Locking (mutual exclusion) is done to prevent two different tasks from simultaneously modifying related database records. Database scanning is the mechanism for deciding when records should be processed. The basics of record processing involves obtaining the current value of input fields and outputting the current value of output fields. As records become more complex so does the record processing.
One powerful feature of the DATABASE is that records can contain links to other records. This feature also causes considerable complication. Thus, before discussing locking, scanning, and processing, record links are described.
A database record may contain links to other records. Each link is one of the following types:
INLINKs and OUTLINKs can be one of the following:
Not discussed in this chapter
A link to another record in the same IOC.
A link to a record in another IOC. It is accessed via a special IOC client task. It is also possible to force a link to be a channel access link even it references a record in the same IOC.
Not discussed in this chapter
A forward link refers to a record that should be processed whenever the record containing the forward link is processed. The following types are supported:
Ignored.
A link to another record in the same IOC.
A link to a record in another IOC or a link forced to be a channel access link. Unless the link references the PROC field it is ignored. If it does reference the PROC field a channel access put with a value of 1 is issued.
Links are defined in file link.h.
NOTE: This chapter discusses mainly database links.
The basic operations which can be preformed on a link (excluding hardware links) are as follows.
A forward link only points to a (normally passive) record that should be processed after the record that contains the link.
For input and output links, two additional attributes can be specified by the application developer: process passive, and maximize severity.
The Process Passive attribute takes the value NPP (Non-Process Passive) or PP (Process Passive). It determines if the linked record should be processed before getting a value from an input link or after writing a value to an output link. The linked record will be processed only if link’s Process Passive attribute is PP and the target record’s SCAN field is Passive.
NOTE: Three other options may also be specified: CA, CP, and CPP. These options force the link to be handled like a Channel Access Link. See last section of this chapter for details.
The Maximize Severity attribute is one of NMS (Non-Maximize Severity), MS (Maximize Severity), MSS (Maximize Status and Severity) or MSI (Maximize Severity if Invalid). It determines whether alarm severity is propagated across links. If the attribute is MSI only a severity of INVALID_ALARM is propagated; settings of MS or MSS propagate all alarms that are more severe than the record’s current severity. For input links the alarm severity of the record referred to by the link is propagated to the record containing the link. For output links the alarm severity of the record containing the link is propagated to the record referred to by the link. If the severity is changed the associated alarm status is set to LINK_ALARM, except if the attribute is MSS when the alarm status will be copied along with the severity.
The method of determining if the alarm status and severity should be changed is called “maximize severity”. In addition to its actual status and severity, each record also has a new status and severity. The new status and severity are initially 0, which means NO_ALARM. Every time a software component wants to modify the status and severity, it first checks the new severity and only makes a change if the severity it wants to set is greater than the current new severity. If it does make a change, it changes the new status and new severity, not the current status and severity. When database monitors are checked, which is normally done by a record processing routine, the current status and severity are set equal to the new values and the new values reset to zero. The end result is that the current alarm status and severity reflect the highest severity outstanding alarm. If multiple alarms of the same severity are present the alarm status reflects the first one detected.
Locking is required to prevent corruption of record fields due to concurrent access by different threads. Record locking can either be done for a single record with dbScanLock, or for a list of records with dbScanLockMany.
Before any record field is accessed, the record must be locked by calling either dbScanLock or dbScanLockMany.
Further details on the algorithms used to implement locking operations can be found in section 5.13.
A single record may be locked for access with a call to dbScanLock and unlocked later with a call to dbScanUnlock.
A thread must only lock one record at a time with dbScanLock, except as discussed in section 5.4.3.
It is possible to lock multiple records safely using dbScanLockMany. First a dbLocker⋆ must be created from an array of record pointers. This object can be used to lock and unlock that particular group of records as many times as necessary with dbScanLockMany.
dbScanLockMany may not be called recursively. After calling dbScanLockMany a thread must call dbScanUnlockMany with the same dbLocker⋆ before calling dbScanLockMany again.
dbScanLock may be called recursively as described in section 5.4.3.
The first argument to dbScanLockMany is an array of dbCommon⋆ (i.e pointers to record instances), and the second is the number of elements in this array. The array may contain duplicate elements. Elements may be NULL.
The third argument to dbScanLockMany (flag) must be zero since no flags are defined at present.
Recursive locking is an attempt by a thread to lock a record which it has already locked. As for example:
But not:
The rules for recursive locking with dbScanLock and dbScanLockMany are as follows:
Therefore the following is valid.
A record is always locked while it is being processed by the IOC. So Device and Record Support code must never call dbScanLock nor dbScanLockMany from within any support callback function.
However, asynchronous device support may explicitly call dbScanLock when the asynchronous operation completes from a user thread or CALLBACK.
The functions dbPutField and dbGetField implicitly call dbScanLock or dbScanLockMany. The functions dbPut and dbGet do not.
All records connected by any kind of database link are placed in the same lock set. Versions of EPICS Base prior to R3.14 allowed an NPP NMS input link to span two different lock sets, but this was not safe when the read and write operations on the field value were not atomic in nature. This feature is no longer available to break a lockset.
Database scanning refers to requests that database records be processed. Four types of scanning are possible:
A dbScanPassive request results from a task calling one of the following routines:
All non-record processing tasks (Channel Access, Sequence Programs, etc.) call dbGetField to obtain database values. dbGetField just reads values without asking that a record be processed.
A record is processed as a result of a call to dbProcess. Each record support module must supply a routine process. This routine does most of the work related to record processing. Since the details of record processing are record type specific this topic is discussed in greater detail in the Chapter “Record Support”.
The ability to link records together is an extremely powerful feature of the IOC software. In order to use links properly it is important that the Application Developer understand how they are processed. As an introduction consider the following example:
Assume that A, B, and C are all passive records. The notation states that A has a forward link to B and B to C. C has an input link obtaining a value from A. Assume, for some reason, A gets processed. The following sequence of events occurs:
This brief example demonstrates that database links need more discussion.
The processing order follows the following rules:
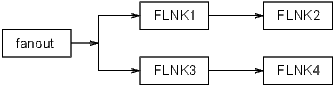
All records, except for the conditions listed in the next paragraph, linked together directly or indirectly are placed in the same lock set. When dbScanLock or dbScanLockMany is called the entire set, not just the specified record, is locked. This prevents two different tasks from simultaneously modifying records in the same lock set.
Every record contains a field PACT. This field is set TRUE at the beginning of record processing and is not set FALSE until the record is completely processed. To prevent infinite processing loops, whenever a record gets processed through a forward link, or a database link with the PP link option, the linking record’s PACT field is saved and set to TRUE, then restored again afterwards. The example given at the beginning of this section gives an example. It will be seen in the next two sections that PACT has other uses.
Input and output links have an option called process passive. For each such link the application developer can specify process passive TRUE (PP) or process passive FALSE (NPP). Consider the following example:
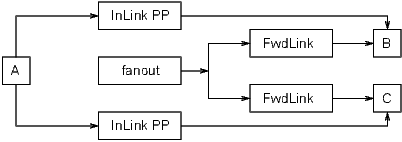
Assume that all records except fanout are passive. When the fanout record is processed the following sequence of events occur:
Note that A was processed twice. This is unnecessary. If the input link to C were declared No Process Passive then A would only be processed once. Thus a better solution would be:
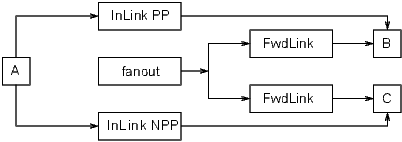
All record type field definitions have an attribute called process_passive which is specified in the record definition file. It cannot be changed by an IOC application developer. This attribute is used only by dbPutField. It determines if a passive record will be processed after dbPutField sets a field in the record. Consult the record specific information in the record reference manual for the setting of individual fields.
Input and output links have an option called maximize severity. For each such link the application developer can specify the option as MS (Maximize Severity), NMS (Non-Maximize Severity), MSS (Maximize Status and Severity) or MSI (Maximize Severity if Invalid).
When database input or output links are defined, the application developer can use this option to specify whether and how alarm severities should be propagated across links with the data. The alarm severity is transferred only if the new severity will be greater than the current severity of the destination record. If the severity is propagated the alarm status is set equal to LINK_ALARM (unless the link option is MSS when the alarm status will also be copied from the source record).
A synchronous record is a record that can be completely processed without waiting. Thus the application developer never needs to consider the possibility of delays when he defines a set of related records. The only consideration is deciding when records should be processed and in what order a set of records should be processed.
The following reviews the methods available to the application programmer for deciding when to process a record and for enforcing the order of record processing.
The previous discussion does not cover asynchronous device support. An example might be a GPIB input record. When the record is processed the GPIB request is started and the processing routine returns. Processing, however, is not really complete until the GPIB request completes. This is handled via an asynchronous completion routine. Let’s state a few attributes of asynchronous record processing.
During the initial processing for all asynchronous records the following is done:
The asynchronous completion routine performs the following algorithm:
A few attributes of the above rules are:
With these rules the following works just fine:

When dbProcess is called for record ASYN, processing will be started but dbScanPassive will not be called. Until the asynchronous completion routine executes any additional attempts to process ASYN are ignored. When the asynchronous callback is invoked the dbScanPassive is performed.
Problems still remain. A few examples are:
Infinite processing loops are possible.

Assume both A and B are asynchronous passive records and a request is made to process A. The following sequence of events occur.
Thus an infinite loop of record processing has been set up. It is up to the application developer to prevent such loops.
A dbGetLink to a passive asynchronous record can get old data.

If A is a passive asynchronous record then record B’s dbGetLink request forces dbProcess to be called for record A. dbProcess starts the processing but returns immediately, before the operation has finished. dbGetLink then reads the field value which is still old because processing will only be completed at a later time.
Consider the following:

The second ASYN record will not begin processing until the first completes, etc. This is not really a problem except that the application developer must be aware of delays caused by asynchronous records. Again, note that scanners are not delayed, only records downstream of asynchronous records.
The rules followed by dbPutLink and dbPutField provide for “cached” puts. This is necessary because of asynchronous records. Two cases arise.
The first results from a dbPutField, which is a put coming from outside the database, i.e. Channel Access puts. If this is directed to a record that already has PACTTRUE because the record started processing but asynchronous completion has not yet occurred, then a value is written to the record but nothing will be done with the value until the record is again processed. In order to make this happen dbPutField arranges to have the record reprocessed when the record finally completes processing.
The second case results from dbPutLink finding a record already active because of a dbPutField directed to the record. In this case dbPutLink arranges to have the record reprocessed when the record finally completes processing. If the record is already active because it appears twice in a chain of record processing, it is not reprocessed because the chain of record processing would constitute an infinite loop.
Note that the term caching not queuing is used. If multiple requests are directed to a record while it is active, each new value is placed in the record but it will still only be processed once, i.e. last value wins.
dbProcessNotify is used when a Channel Access client calls ca_put_callback and makes a request to notify the caller when all records processed as a result of this put are complete. Because of asynchronous records and conditional use of database links between records this can be complicated and the set of records that are processed because of a put cannot be determined in advance. The processNotify system is described in section 15.4.3.3 on page 530. The result of a dbProcessNotify with type putProcessRequest is the same as a dbPutField except for the following:
A channel access link is:
A channel access client task (dbCa) handles all I/O for channel access links. It does the following:
Even if a link references a record in the same IOC it can be useful to force it to act like a channel access link. In particular the records will not be forced to be in the same lock set. As an example consider a scan record that links to a set of unrelated records, each of which can cause a lot of records to be processed. It is often NOT desirable to force all these records into the same lock set. Forcing the links to be handled as channel access links solves the problem.
CA links which connect between IOCs incur the extra overhead associated with message passing protocols, operating system calls, and network activity. In contrast, CA links which connect records in the same IOC are executed more efficiently by directly calling database access functions such as dbPutField and dbGetField, or by receiving callbacks directly from a database monitor subscription event queue.
Because channel access links interact with the database only via dbPutField, dbGetField and use a database monitor subscription event queue, their interaction with the database is fundamentally different from database links which are tightly integrated within the code that executes database records. For this reason and because channel access does not support the passing of a process passive flag, the semantics of channel access links are not the same as database links. Let’s discuss the channel access semantics of INLINK, OUTLINK, and FWDLINK separately.
The options for process passive are:
Maximize Severity is honored.
The options for process passive are:
Maximize Severity is not honored.
A channel access forward link is honored only if it references the PROC field of a record. In that case a ca_put with a value of 1 is performed each time a forward link request is issued. Because of this implementation, the requirement that a forward link can only point to a passive record does not apply to channel access forward links; the target record will be processed irrespective of the value of its SSCAN field.
The available options are:
Maximize Severity is not honored.
This section describes details of the implementation of dbScanLock and dbScanLockMany. Any discussion of links and linking in this section refers only to database links (DB_LINK). Other link types do not require record locking.
A lockset guards one or more records with an epicMutexId. Each lockset maintains a list of its member records.
The relationship between a record and a lockset forms the basis of the locking algorithms. Every record is always a member of some lockset throughout its lifetime. However, a record may move between locksets. The relationship between record and lockset is established in the lockRecord⋆ private structure which is the LSET field of each record. Each lockRecord structure includes an epicsSpin⋆ to maintain its consistency.
Records are associated with each other through links with the DBF_INLINK, DBF_OUTLINK, and DBF_FWDLINK field types. These links are directional, from the record with the link field, to the field of the record it is targeted at. This is a directed graph of records (nodes) and links (edges).
The existence of a database link between two records places them in the same lockset. This allows database processing chains involving multiple records to maintain consistency. Records which are not currently connected by any database link (directly or indirectly) are placed in different locksets. This enables parallel scanning of unrelated processing chains.
When a database link is created between two records in two different locksets, all the records in the locksets are moved into one lockset. The other (now empty) lockset is free’d. This is referred to as a merge operation.
Each time a database link between two records is broken it is possible that the lockset (graph) has become partitioned (split in two). When this occurs, a new lockset is created and populated with one set of connected records. This is referred to as a split operation.
Access and modification of the association between record and lockset is governed by the following rules:
A basic property of a spin lock is that it must not be held during any blocking operation, including locking a mutex. This defines the order of locking. The mutex (lockset) must be locked first, then the spinlock (lockRecord).
This complicates things because locking operations begin with record pointer(s) (dbCommon⋆). The spinlock must be locked first in order to find a record’s current lockset. However, the spinlock must be unlocked before the lockset can be locked. Care must be taken as the association may change when neither is locked. Furthermore, when two locksets are merged, one of them will be free’d.
To handle this safely, each lockset contains a reference counter. The lockset will only be free’d when this counter falls to zero. This counter has one “count” for each active reference. Each lockRecord is an active reference. Further, a dbLocker may also hold active references.
The process of locking a lockset is as follows:
There remains the possibility that the association between record and lockset may change during the moment between unlocking the spinlock and locking the mutex. This can be detected after the mutex has been locked. When it occurs, the whole operation must be re-tried with the new lockset.
We assume that database link modification is a relatively rare operation.
Locking multiple locksets is necessary when a database link is created. The underlying epicsMutex API only supports locking a single mutex in one call. Care must be taken to avoid a deadlock when locking the second, and beyond.
Two common strategies for avoiding deadlocks are to use a try-lock operation with ownership tracking, or to establish a global ordering. At present the second strategy is used. All lockset mutexes are placed into a global order by comparing their memory (pointer) address. Locking is done in order of increasing address.
Merging two locksets when a link is created is accomplished by locking both locksets, then concatenating their record lists into one. This leaves one empty lockset.
Splitting one lockset into two when a link is broken requires finding if the lockset has become partitioned. It is helpful to recognize that the act of removing one link between two records (say ‘A’ and ‘B’) can result in at most two locksets.
To determine if a lockset has been partitioned it is sufficient to start with one of the two records (‘A’), then recursively traverse the remaining links to or from record ‘A’. If record ‘B’ is encountered during this traversal, then the lockset has not been partitioned. If all records connected to ‘A’ can be traversed without finding ‘B’, then the lockset has been partitioned. All the records connected with ‘A’ become one lockset, while the remaining records (including ‘B’) become the second.
During IOC startup, the complete list of records is iterated (by dbLockInitRecords) and the required locksets are created and populated based on the links defined at the time.